08. How to Monitor Guardrails

8.1 Overview
This section provides an overview of the key process steps to effectively monitor guardrails. After deploying guardrails into production on AI systems, it is critical to conduct continual monitoring, as well as periodic weekly, monthly, and quarterly assessments of guardrail effectiveness and to validate they are working as intended. Through this process, additional guardrail requirements may be identified in order to mitigate risks.
8.2 High-Level Process and Common Pitfalls
The following 5 high-level process steps of monitoring guardrails includes:

Common Pitfalls
Following the above process helps ensure accurate and thorough system monitoring, with effective incident resolution. Failure to incorporate the above process can lead to pitfalls, including:
- Inaccurate Metrics and Reporting: A poorly constructed monitoring system may lead to inaccuracies in reported metrics.
- Failure to Detect and Resolve Incidents: Without a proper pipeline for incident management, high risk incidents may be left uncaught, exposing the enterprise to potential operational or regulatory risk.
- Ineffective Policies: Without continual monitoring, policies may fail to achieve their intended outcomes, reducing the guardrails’ effectiveness in mitigating risks.
- Performance Drift: Without continual monitoring and feedback incorporation, system performance may deviate, or ‘drift’, from performance benchmarks over time.
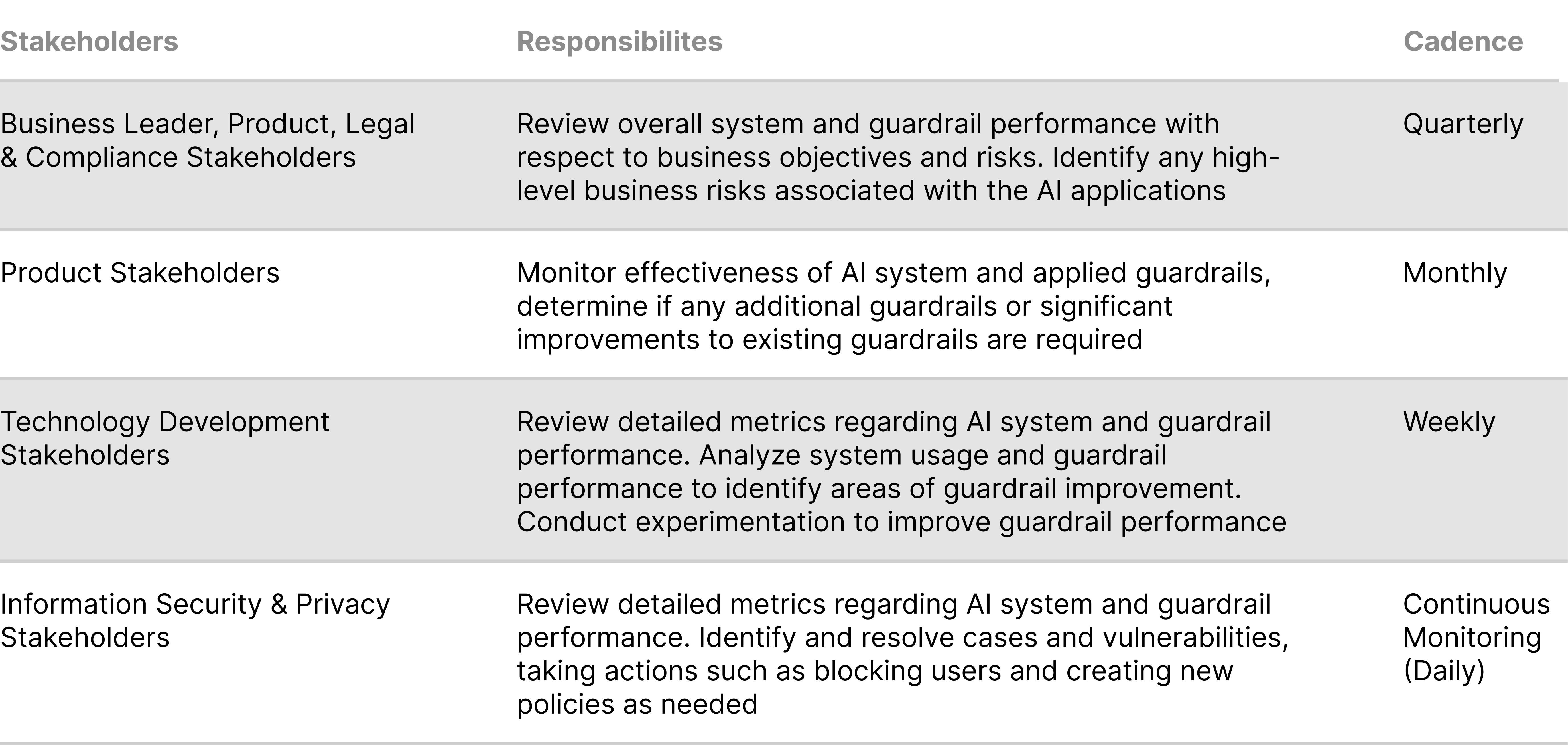
8.3 Roles and Responsibilities
Monitoring guardrails in production requires the involvement of various stakeholders across technology, business, and risk management domains. The specific stakeholders involved may vary depending on organizational structure, but the following stakeholders are required.
After guardrails have been created and deployed, the following stakeholders should be involved in continual monitoring:
💡 Estimating Resource Effort
The number of stakeholders aligned to ongoing monitoring of guardrails is dependent upon a number of factors including the AI use cases enabled, the volume of guardrails implemented, AI use case user volumes, the size and complexity of the enterprise, the risk tolerance of the enterprise, and the regulatory regimes in which it operates. Best practice requires a model where clear accountable owners for each functional process is required, with an assessment completed to identify resource requirements alongside documented strategies to effectively scale.
For some enterprises, initial effort is spent on integrating guardrail monitoring data into existing AI evaluation or reporting frameworks (process and technology). This is a cross functional effort where enterprises will spend 1 -4 weeks dedicated to design and implementation, which often involves considerations beyond guardrail data integration.
In addition to this, implementing 5 guardrails may require:
- 3 – 5 hours per week assigned to monitor incidents, manage reporting and escalation to various stakeholders.
- 2 - 4 hours per week for a Technology Development Stakeholder to monitor guardrail drift, support guardrail enhancements, and suggest and implement guardrail improvements.
In addition to these primary allocations, support from stakeholders who have provided policy-based definitions may also be required for input or assessment.
8.4 Playbook Detail: Monitoring Guardrails
There are five main components required for effective guardrail monitoring.
8.4.1 Data Capture Setup
Data Requirements
Guardrail monitoring requires comprehensive but lean data workflows for it to be effective and efficient. Given the amount of data that can be generated by an AI system in production, it is critical that teams are intentional in what data they collect, how it is collected and stored, and finally how it expires. The two sections below provide the next level of detail on what needs to be captured and how it should be integrated into the broader workflow.
What Data Should be Captured?
As outlined in the methodology section above, guardrail monitoring has several objectives, with differing data requirements. For example, to enable measurement of guardrail effectiveness, teams need to capture assessment outcomes with scores that led to that outcome. Whereas for incident management, teams need to capture timestamps, user ids, AI system ids that can trigger patterns of anomalous usage. While compiling requirements, it is critical that teams start from each guardrail monitoring objective and then walk back.
Guardrail assessment data is generated like a data stream, every time an assessment is made, a datapoint is published detailing the analysis and the outcome. The core decisions enterprises must make revolve around these independent datapoints and what metadata they should capture. Dynamo AI recommends the following metadata to be packaged and published as a datapoint every time an assessment is made - and provides it with its suite.

How Should Data be Integrated?
After establishing a blueprint of the datapoints that are going to be generated, enterprises need to establish how these will be ingested, used and retired by the broader AI workflow they utilize. This again depends on the monitoring objectives, but for the purposes of integrations they can be generalized as follows:
- Real-Time Scenarios: Data that is going to be used for real time scenarios, like detection of anomalies and creation of cases based on those.
- Ad Hoc Analysis Scenarios: Data that is going to be used in ad-hoc analysis with no real-time requirements, like analysis of assessment history for guardrail evaluations.
Note that the data that powers both use cases are the same. What differs here is the data workflows and tools that power these scenarios, and how the data might be transformed to fit the needs of the working group.
Products like DynamoGuard often offer both integration options, and teams often leverage both integrations.
Real-time data is provided in the form of logs just as the assessment is made, published to the teams’ data platform of choice through a solution like FluentBit or Logstash that both sides can configure. Teams then can build processes like anomalous event detection on top.
Historical data is provided through some form of database or data store like MongoDB or S3. Teams then build processes and applications on top of these, like an efficacy assessment tool or periodic activity visualization tool.
8.4.2 Guardrail Monitoring
Ensuring that policies continually perform as intended is critical to maintaining the safety and compliance of AI systems. The section provides an overview of the methodologies for monitoring and evaluating effectiveness of deployed guardrails as well as the key metrics to evaluate.
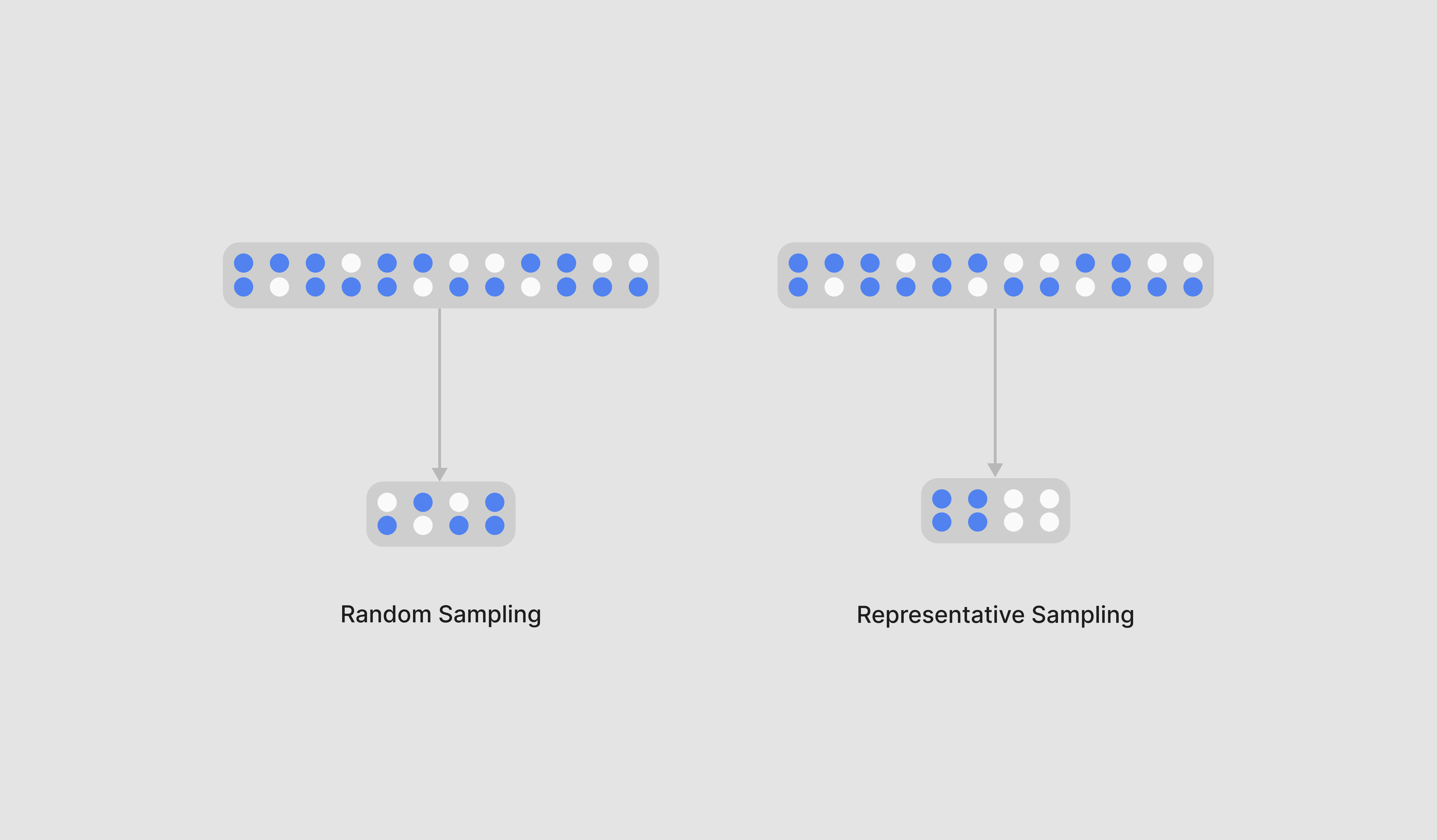
Sampling Strategies
Generally, guardrails may be applied to many AI systems and may be responsible for guardrailing millions of user inputs and model responses on a daily basis. To efficiently measure guardrail effectiveness, it is critical to sample a subset of user inputs and model responses that were run through an AI system. A statistically significant sample size should be selected and analyzed to ensure sample validity, based on the original data volume and the target margin of error. The following sampling strategies can be used:
- Random sampling: Selecting a random subset of data. This is a simple sampling strategy but may miss certain nuances or categories of data because of the nature of the selection.
- Representative sampling: Selecting a random subset of data such that all key segments, such as user groups, guardrail types, and edge cases are adequately represented.
Section 6 also provides best practice to assess and monitor for guardrail definition quality and data point validation.
Metric Calculation
After extracting a representative sample of the system data, the following metrics should be assessed. These metrics can be assessed on a rolling cadence. Note that these metrics are similar to the offline guardrail evaluation metrics.
To calculate the following metrics, it is necessary to first assess the true compliance status of each datapoint. The true compliance status of a datapoint is the manually validated label that stakeholder responsible for review determine relative to the guardrail being assessed. Having multiple reviewers can help improve label confidence.

8.4.3 Incident Management
To ensure effective incident management, it is necessary to have a thorough process for case identification, as well as for case creation and resolution. This section outlines strategies for case identification for both guardrail violations and anomalous usage and also provides an overview of the case creation and resolution process.
Incident Types
In addition to general metrics, it is also critical to identify security or compliance incidents based on live system performance.
The key incident types that should be tracked are the following two components:

- Guardrail Violations: User inputs or model responses that violate policies
- Caught Violations: guardrail violations that were successfully detected (True Positives)
- Uncaught Violations: guardrail violations that were not detected by the system (False Negatives)
- Anomalous Usage: Usage of the AI system that does not reflect regular usage patterns
- User anomalies: anomalous patterns of usage related to a single user, such as many rapid violating queries
- System anomalies: anomalous patterns of usage related to the overall system, such as unexpected spikes in system usage or guardrail violation
Guardrail Violation Case Identification
To identify guardrail violation incidents, enterprises should assess and analyze a subset of data. For incident management, analysis should be conducted at a daily cadence at minimum. Additionally, it can be more powerful to apply the following sampling techniques:
- Representative sampling: Selecting a random subset of data such that all key segments, such as user groups, guardrail types, and edge cases are adequately represented. This can be used for detecting both caught and uncaught violations.
- Uncertainty Sampling: Prioritizing data where the system demonstrates low confidence in the guardrail decision. This can be best used for detecting previously unidentified violations.
- Anomaly-Detection-Based Sampling: Prioritizing data that is an outlier or is dissimilar to the average datapoint in the system.
Anomalous Usage Case Identification
For incidents regarding anomalous usage, it’s important to detect incidents more urgently as they occur. As a result, automated analysis should be conducted in real-time and should focus on automated outlier detection using statistical or machine learning anomaly detection methods.
Examples:
20% increase in violations per hour
- User with > 50 prompts in a minute
- User with > 100 violations over all time
💡 Case Creation and Resolution
Case resolution and resolution should involve the following steps:
- Daily Case Creation: A subset of sampled data should be audited daily to identify critical incidents regarding guardrail violations. At the same time, anomaly detection mechanisms should be run on a continuous cadence to identify incidents around anomalous usage.
- Immediate Actions: For critical incidents, it can be important to apply urgent measures such as blocking or throttling users or even disabling a system. Once an anomaly is detected — the user or system can be automatically blocked or disabled.
- Root Cause Analysis: Investigate system or recurring issues using system logs and incident reports.
- Longer-term Remediation: Update policies, adjust AI system models to improve incident detection.</aside>
8.4.4 Reporting
Transparent reporting is critical for ensuring that AI guardrails remain effective and aligned with stakeholder expectations. This section provides an overview of the key metrics to report on both guardrail effectiveness and incident resolution.
Guardrail Effectiveness
To report on the performance of policies to external stakeholders periodically, the following metrics should be assessed. These metrics should be representative of both guardrail effectiveness and incidents detected.

Incident Resolution

8.4.5 Guardrail Improvement
The final step in guardrail monitoring is leveraging data and insights regarding the system performance to refine policies. It can be helpful to analyze the data above across dimensions such as user groups, policies, or languages to identify patterns regarding uncaught guardrail violations or false positives. These trends can be used to identify gaps in existing policies. For more details regarding guardrail improvement, see Section 6.4.4 on guardrail implementation and Section 7 on evaluation of guardrails.
8.5 Success Criteria
The following table provides success criteria for executing Guardrail monitoring.



.webp)
