06. How to Create Policy Guardrails

6.1 Overview
Creating and implementing effective policy-based guardrails is essential for secure, responsible, and reliable deployment of AI. This section outlines the process of policy-based guardrail creation, providing best-practices and organizational processes for identifying relevant guardrails, defining guardrails, implementing guardrails, and continuous guardrails refinement.
6.2 High-Level Process and Common Pitfalls
High-Level Process
To establish effective guardrails for AI governance, enterprises should follow these 4 key steps:

After creating policy-based guardrails, it is also important to evaluate guardrail performance and regularly monitor and refine guardrails to address gaps, improve performance, and adapt to emerging risks and regulatory changes. In this Section best practices for guardrail creation are outlined. For detail on the evaluation of guardrails and guardrail monitoring, see Sections 7 and 8.
Common Pitfalls
Executing the high-level process steps outlined leads to a high-performant, comprehensive set of guardrails, and has been developed as a result of ongoing partnerships with regulated enterprises deploying guardrails. Not following this process may lead to several pitfalls, further described below.
- Incomplete Risk Assessment: Failing to conduct a thorough risk assessment can lead to gaps or redundancies in guardrails, leaving critical risks unaddressed.
- Lack of Control Evidence: Without conducting a risk assessment and creating well-defined guardrails, it becomes difficult to demonstrate compliance, establish controls, confirm required control evidence, or define exit criteria for processes.
- Ineffective Policy Design: Poorly defined or implemented policies may fail to achieve their intended outcomes, reducing the guardrails’ effectiveness in mitigating risks.
- Inefficient Implementation: Building guardrails in-house can be costly, resource-intensive, and prone to errors. Leveraging tools or platforms like Dynamo AI ensures more reliable and scalable implementation.
6.3 Guardrail Creation Approaches and Roles and Responsibilities
There are three common governance structures for guardrail creation: centralized, decentralized, or hybrid. The chosen governance structure affects the responsibilities of each stakeholder in the process. The following diagram provides an overview of each approach along with each of the advantages and disadvantages.
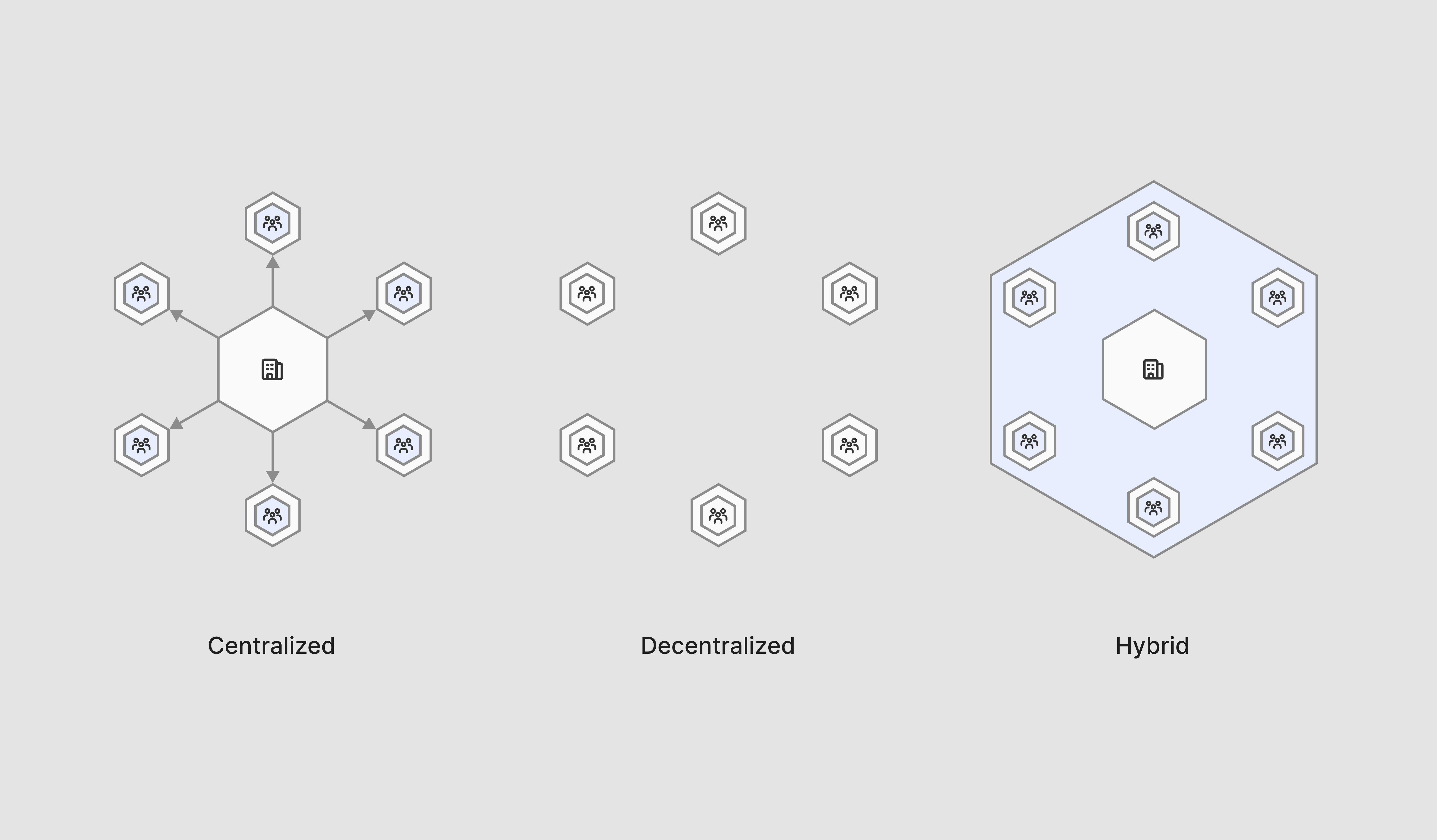
Centralized
Guardrails are identified, defined, validated, and implemented by a leadership or centralized cross-functional working group. Guardrails are then applied to all AI use-cases within the enterprise.
Advantages:
- Guardrails are consistent across enterprise
- Simplifies governance with unified operating model
Disadvantages:
- Risk of slower implementation with centralized decision-making
- May not account for unique needs of individual teams/use-cases
Decentralized
Guardrails are identified, defined, validated, and implemented by individual teams, based on AI system specific contexts. Guardrails may still be validated or reviewed stakeholders with specific subject matter expertise, such as information security or legal and compliance stakeholders.
Advantages:
- Allows enterprises to tailor guardrails to their specific needs and contexts
- Simplifies implementation process
Disadvantages:
- Risk of inconsistency across enterprise
- Enforcing and auditing compliance is more difficult
Hybrid
A combination of a centralized and decentralized approach is taken. The centralized approach is used for establishing enterprise-wide guardrails, while the decentralized approach is used for establishing additional guardrails for specific use-cases or regions.
Advantages:
- Organizational-wide consistency with tailored solutions
Disadvantages:
- Complexity of coordination between centralized and decentralized guardrails
- May require more resources to manage
Centralized Approach: Implementation Responsibilities
In the centralized approach, a cross-functional AI working group focused on AI safety and governance should collaborate to identify, define, validate, and implement guardrails.
- Identification and Definition: Product, Technology Development, Information Security & Privacy, Risk Management, and Legal & Compliance should all be involved in guardrail identification. Each stakeholder group should be responsible for outlining and providing a detailed definition of the guardrails based on their expertise.
- Validation: Product, Technology Development, Information Security & Privacy, Risk Management, and Legal & Compliance should all be involved in guardrail validation. Teams with broader oversight, including Risk Management should review and validate guardrails created by other groups. Deduplication or consolidation should also be done at this step.
- Implementation: Product, Technology Development, Information Security & Privacy, Risk Management, and Legal & Compliance should all be involved in guardrail implementation. Analysts in each group are separately responsible for implementing their defined guardrails, using platforms like DynamoGuard.
Decentralized Approach: Implementation ResponsibilitiesIn the decentralized approach, AI system-specific teams should identify, define, validate, and implement guardrails. Here, we define the AI system-specific team as the Product and Technology Development stakeholders working on the particular AI system.
- Identification and Definition: Product and Technology Development stakeholders should be involved in guardrail identification. Each stakeholder should be responsible for outlining and providing a detailed definition of the guardrails based on their expertise.
- Validation: Even in the decentralized approach, it is recommended that centralized groups involving functions such as Risk Management, Information Security & Privacy, and Legal & Compliance should review and validate that guardrails have been established to effectively mitigate identified risks.
- Implementation: Product and Technology Development stakeholders within the AI system-specific team are responsible for guardrail implementation, using platforms like DynamoGuard.
Hybrid Approach: Implementation Responsibilities
In the hybrid approach, a cross-functional set of stakeholders (often in the form of an AI governance and or safety working group) should collaborate to identify, define, validate, and implement guardrails that should be applied to all AI use-cases within the enterprise. Meanwhile, AI system-specific stakeholders should identify, define, validate, and implement use-case specific guardrails. The appropriate model (centralized or decentralized) should be followed as outlined above. Below is an example implementation of a hybrid approach for a financial chatbot AI system focused on answering customer account queries.
Estimating Resource Effort
Estimating and assigning an appropriate number of resources to create guardrails should be aligned to an enterprise’s size and complexity, and the volume and complexity of AI use cases prioritized. That being said, a typical AI use case (for example, an internal knowledge chatbot) where 5 guardrails are required may see the following resource allocation over the course of a 4-week creation process:
- Estimated 2 hours per week per policy-based guardrail for one Product or Technology Development Stakeholder to oversee the creation process. This includes reviewing and working to assess any embedded or ‘out of box’ guardrails available. This amounts to 10 hours per week for 5 estimated guardrails.
- Estimated 2 hours per guardrail for guardrail design or validation by relevant subject matter experts including Risk Management, Information Security & Privacy, or Legal & Compliance Stakeholders. Each guardrail may include a single stakeholder group where that estimated 2 hours would be split across multiple stakeholders. For 5 guardrails, this would amount to 10 hours of total effort across the 4 weeks.
- 2 - 4 hours per week for Technology Development Stakeholders to support any technical or training inquiries that may result in the process. For the creation of 5 guardrails over 4 weeks, this would amount to 8 – 16 total hours of effort.
6.4 Playbook Detail: How to Create Guardrails
The following sections walk through detailed best practice for how to create guardrails.
6.4.1 AI Use Case Risk Assessment
To determine the specific guardrails to apply to the AI system, the following steps must be executed:
- Conduct an AI Use Case Risk Assessment: Identify and document risks related to the deployment and use of an AI system to identify required guardrails.
- Map Risks to Guardrails: Map identified risks to guardrails.
- Assess Business Impact: Determine the business impact of each risk and associated guardrail, prioritize guardrails to develop.
Step 1: Conduct an AI Use Case Risk Assessment
Enterprises should assess the risks of deploying AI use cases across a comprehensive risk taxonomy, as noted in Section 4. This is a cross-functional exercise that looks at considerations such as operational, financial, strategic, legal, security, compliance, reputation, and technology risks, to name a few. As a part of this evaluation, enterprises should identify the types of guardrails that may be required to mitigate the risks identified as part of the AI Use Case Risk Assessment process, leaving the enterprise with a residual risk that may be acceptable. To start this process, document the risks of the AI system, along with specific examples and the severity of the risk. To determine the risks associated with the AI system and work to identify what types of guardrails may be required, it is important to ask the following questions:
- Is the AI system external-facing or internal-facing?
- External-Facing Systems, such as customer-facing chatbots, have higher risks of security and model misuse, as well as higher business impacts of model hallucination or non-compliance.
- Internal-Facing Systems, such as employee productivity tools, generally have lower risks, but there may be higher data-privacy risks related to the leakage of internal sensitive information.
- What is the interaction model of the AI system?
- Systems that directly interact with users/customers vs. systems that have a human-in-the-loop component may have different risks.
- Where is the AI system being deployed?
- Different regions have different regulatory requirements. For example, it is critical to align with General Data Protection Regulation (GDPR) and the EU AI Act. Geographies with stricter laws and regulations will require additional guardrails.
- What industry is the AI system being deployed within?
- Systems in domains with higher regulatory requirements, such as financial services or healthcare, will require specific guardrails for compliance with sector-specific regulations.
- Does the AI system deal with sensitive data?
- Systems dealing with sensitive information, such as customer account data, will require additional guardrails for safeguarding the sensitive data.
Asking these questions can help determine broader risk considerations for the AI system which will feed into the overall AI Use Case Risk Assessment process.
Step 2: Mapping Risks to Guardrails
After outlining the risks of the AI system, a review to determine which of these risks can be mitigated through guardrail policies must be completed. Not all risks can be controlled through guardrail policies — however risks tied to user inputs and model responses can be mitigated.
For identified risks where a guardrail may serve as a control, a guardrail should be created. Risks that originate from users should map to input guardrails, which are applied to user inputs. On the other hand, risks that originate from models should map to output guardrails, which are applied to model responses. The below table provides an overview of common risks that are addressable by guardrails.
Common Risks of Generative AI Systems
Step 3: Identify Business Impact
To prioritize guardrail creation, enterprises must assess the downstream business impact of identified risks and policies. Business impact can help determine the importance of creating related guardrails to address the risk. Each risk can lead to business impacts such as:
- Legal, Regulatory, or Compliance Violations: Violation of laws, regulations, or compliance standards. This is the most severe business impact and may lead to material regulatory, financial, reputational, or legal risk.
- Reputational Harm: Impact to the reputation of the enterprise
- Product Quality: Degradation in the quality of the AI system.
Example: Financial Services Customer Account Question and Answer Chatbot
In the table below, an example of a risk assessment is provided, along with sample guardrails for remediation. Note: the following is not meant to be comprehensive.
Tips
There is a trade-off between creating many granular guardrails versus a few broad (or blunt) guardrails. For example, a single broad guardrail could state ‘Prohibit Sensitive Information’, while more broad guardrails might include ‘Prohibit Sensitive User Financial Data Disclosure’ or ‘Block Requests Containing Social Security Numbers”. Granular guardrails may have more precise protection and higher performance, however; each additional guardrail will introduce additional latency and inferencing costs. The coverage versus overhead trade-off decision should be made at an AI system-level.
6.4.2 Guardrail Definition
As previously noted, a crucial step in developing guardrails is identifying the risks they should protect against. This is done outside of the Dynamo AI platform.
Writing well-crafted policies for guardrails
Once guardrails have been identified as per the AI Use Case Risk Assessment process, they must be translated into Dynamo-ready policy-based guardrail definitions. The policy is the guardrail definition, including what is allowed and not allowed, that is a core part of an effective guardrail. The goal of this process is to create guardrails that are as interpretable and clear as possible for our models to learn and enforce. To achieve strong performance, guardrails should easily enable humans to label the compliance status of example inputs and outputs. Guardrail creation is an iterative process, as key stakeholders ensure that the written guardrail and generated data align with their expectations.

Tailor policies towards either input or output. For a guardrail such as Prohibit Financial Advice, the description and behaviors used to block inputs that solicit financial advice versus outputs that provide financial advice are likely different. They may be different both in content as well as in style — for example, inputs might often be in the form of a question. These differences should be reflected in a guardrail.
Considerations for Writing Descriptions
The guardrail description should define what the guardrail is enforcing, as well as key terms critical to the understanding of the guardrail. This information may come directly from internal policy documents or legal documentation.
Considerations for Writing Use Cases
Adding a use case is extremely helpful for developing a well-performing guardrail. This helps ground our models in the actual deployment scenario. A use case should describe the application and domain the guardrail is being applied to. An example is a "financial services call center” use case.
Considerations for Writing Behaviors
Behaviors are a critical component of a guardrail definition. These provide more detail around the specific behaviors that are allowed or disallowed. They break down the guardrail into granular chunks. Behaviors should be grounded in the domain/use case as well as the general description. For example, a guardrail focused on a financial product’s customer support application should include Allowed Behaviors that reference typical customer or system actions that are expected in this domain and use case. Aim for 5 - 10 behaviors per Allowed and Disallowed each.
Tips
- The technology used to create guardrails may also be able to synthetically “generate behaviors” as part of its functionality in the guardrail creation process. This is where Allowed and Disallowed behaviors are automatically created by using provided definition and domain / use case details. This is a good way to validate the definition.
- Adding a category label before the text of a behavior is useful for organizing behaviors and communicating big picture concepts to our models. For example:
- Insurance advice: advice regarding insurance.
- Investment advice: advice regarding investments.
- There must be behaviors that describe generally allowed behavior based on the domain / use case. This allows the model to develop a good sense of what compliant data may look like. Even though you may be focused on noncompliance, you must think about what compliance looks like to get good performing models that can differentiate between the two.
- Allowed Behaviors that skirt the line of the guardrail help define the limits of what is allowed versus disallowed.
- For example, a Prohibit Tax Advice guardrail may allow an AI system to mention due dates for taxes, but not to advise an individual to file their taxes by a certain date. The difference here is between fact and a piece of advice.
- It is helpful to base Disallowed Behaviors on the research and risk-mapping that underlines the guardrail development.
- It is important to write as many Disallowed Behaviors as necessary to cover all major categories of disallowed behaviors that fall under a particular guardrail. Make sure to be as specific and targeted as you can.
- For example, the Prohibit Financial Advice guardrail’s disallowed behaviors cover many different types of financial products and activities:
- Providing guidance or strategies about how to select financial products or services
- Providing any response construed as advice or recommendations regarding [choose one or multiple] investing or investments / corporate finance / financial markets / investment banking / financial / compliance regulation / lending and credit / consumer banking / wealth management / etc.</aside>
6.4.3 Guardrail Validation
Example Review
Once there is a guardrail definition created within DynamoGuard, the next step in the platform is to ensure that the human interpretation of the definition is aligned with an AI model’s understanding of it. This involves both assisting guardrail creators in identifying gaps in their guardrails to edit as well as providing feedback on data that guardrail models can learn from. Ultimately, this step is critical because it will shape the training data that the resulting guardrail model learns from.
Process
Ensuring human-AI alignment on the guardrail definition involves pressure-testing the guardrail with datapoint examples that represent edge cases and borderline scenarios. The platform will use the guardrail definition to synthetically generate a small number of such datapoints — prompts if the model is for input and prompts and responses if the model is for output. The primary individual responsible for creating the Dynamo-ready guardrail definition should be responsible for going through the example review process. This individual goes through each example and labels them as compliant or noncompliant with the guardrail. The DynamoGuard platform requires an equal number of datapoints marked as compliant and noncompliant in order to accurately shape the human-AI alignment step.
During example review, the guardrail creator has a chance to refine the guardrail if necessary. They should take care to base their compliance decisions on the guardrail as written, not as they wish it. A very clear way to ensure this is to make sure that when they mark an example as noncompliant, they can easily select a Disallowed Behavior that is violated. If they mark an example as compliant, they should be able to point to an Allowed Behavior that is followed. If they cannot, this is a strong sign to return to the guardrail-editing stage to amend the guardrail.
Training Data Review
Update synthetic training data to align with the guardrail definition if necessary. This is the final step before kicking off training of the guardrail model.
Process
After example review, the DynamoGuard platform generates a full set of training data (around 1,000 datapoints). This data spans several categories of data from training data that represents compliant examples to data that is modeled after a potential jailbreak attack. Each datapoint may be relabeled before being used for training. It is recommended to review as many of these training datapoints as possible. While the DynamoGuard synthetic data generation strategy is highly performant, human-in-the-loop processes allow enterprises to granularly customize policies, bolster confidence in guardrails, and serve a useful auditing function. In the process of reviewing training data and potentially relabeling, follow the best practices laid out in the examples provided within this section. If patterns emerge in data that is being relabeled, such as a topic or style of example that systematically is mislabeled, this may be an indication the guardrail definition needs to be amended.
After this process is completed, guardrail training will commence.
6.4.4. Guardrail Implementation
Iterative Guardrail Improvement
It is essential to continuously improve guardrails in response to evaluations, performance in real-world scenarios, and emerging risks. Section 7 details the formal evaluation process to benchmark a guardrail and Section 8 provides guardrail improvement considerations throughout the monitoring process. The following detail provides guidance specifically on a best practice for assessing the quality of the guardrail definition and accompanying data points (developed within this section), which is helpful for honing best practice policy-based guardrail creation.
Process
Once a guardrail has been deployed into production, real-time usage logs should be generated and stored. Each log should include a model-generated label noting it as noncompliant or compliant. The team responsible for reviewing and auditing these logs should provide feedback, noting datapoints they disagree with the guardrail model on. These are mislabeled datapoints. Mislabeled datapoints can be results of the model’s misunderstanding of the guardrail (Type 1 Errors) or point to a gap within the guardrail itself (Type 2 Errors).
To identify the root cause of mislabeling, the responsible team should first review the mislabeled datapoints and identify recurring patterns.
For example, for a “Prohibit Financial Advice” guardrail, the following patterns may be identified: (1) Examples that reference insurance advice are mislabeled as compliant and (2) Examples with an informal tone are mislabeled as compliant.
Once these trends have been identified, they can be used to improve the guardrail. Patterns of Type 1 point to a topic area or edge case that the guardrail currently does not cover. In the “financial advice” example, there is no behavior that covers insurance specifically. Therefore, the guardrail should be updated with the new behavior, additional data should be generated, and the guardrail should be retrained. In the case of Type 2 patterns, the guardrail is still correct, but the guardrail needs additional training data to reflect data with an informal tone.
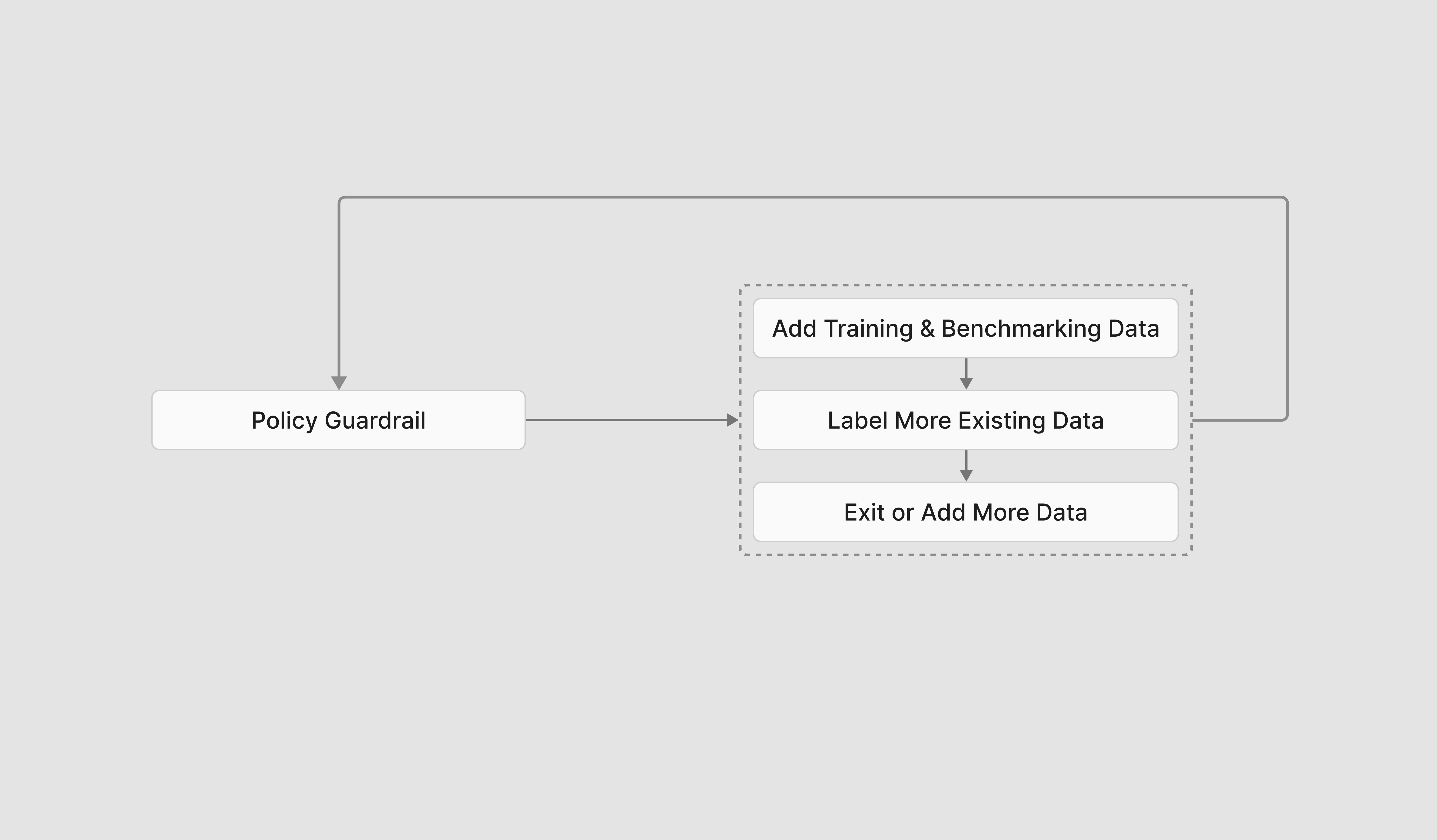
Below is an overview of the main ways to improve guardrails as a result of patterns of mislabeled data.
Methods to Improve Guardrails
Add training and benchmark data that aligns with the given product and use case. Training and benchmark data that is similar to the data you expect to come through your guardrailed product is the most important element of a well-trained guardrail. This ensures that the guardrail model understands the distribution of data that is most relevant to your product.
Tips
Key elements to keep in mind:
- Balanced dataset of noncompliant and compliant data. Datasets that cover both compliant and noncompliant examples are essential so that the model understands the differences between the two.
- Data should be similar in tone, style, and content to the data expected in your product.</aside>
Adding new training data requires retraining your model. Adding new benchmark data requires testing against that benchmark again. Section 7 provides further detail on benchmark data set creation and review.
- Label more existing synthetic training datapoints Updating labels of existing training datapoints can help the guardrail model understand better how to gauge noncompliance and compliance. Once you’ve relabeled datapoints, you must kick off the training process once more.
- Edit or add guardrail behaviors Edit behaviors or add behaviors to your guardrail if you want to expand coverage of your guardrail to new topics or edge cases or amend how it deals with already-covered topics. Once you do this, you must regenerate data and retrain.
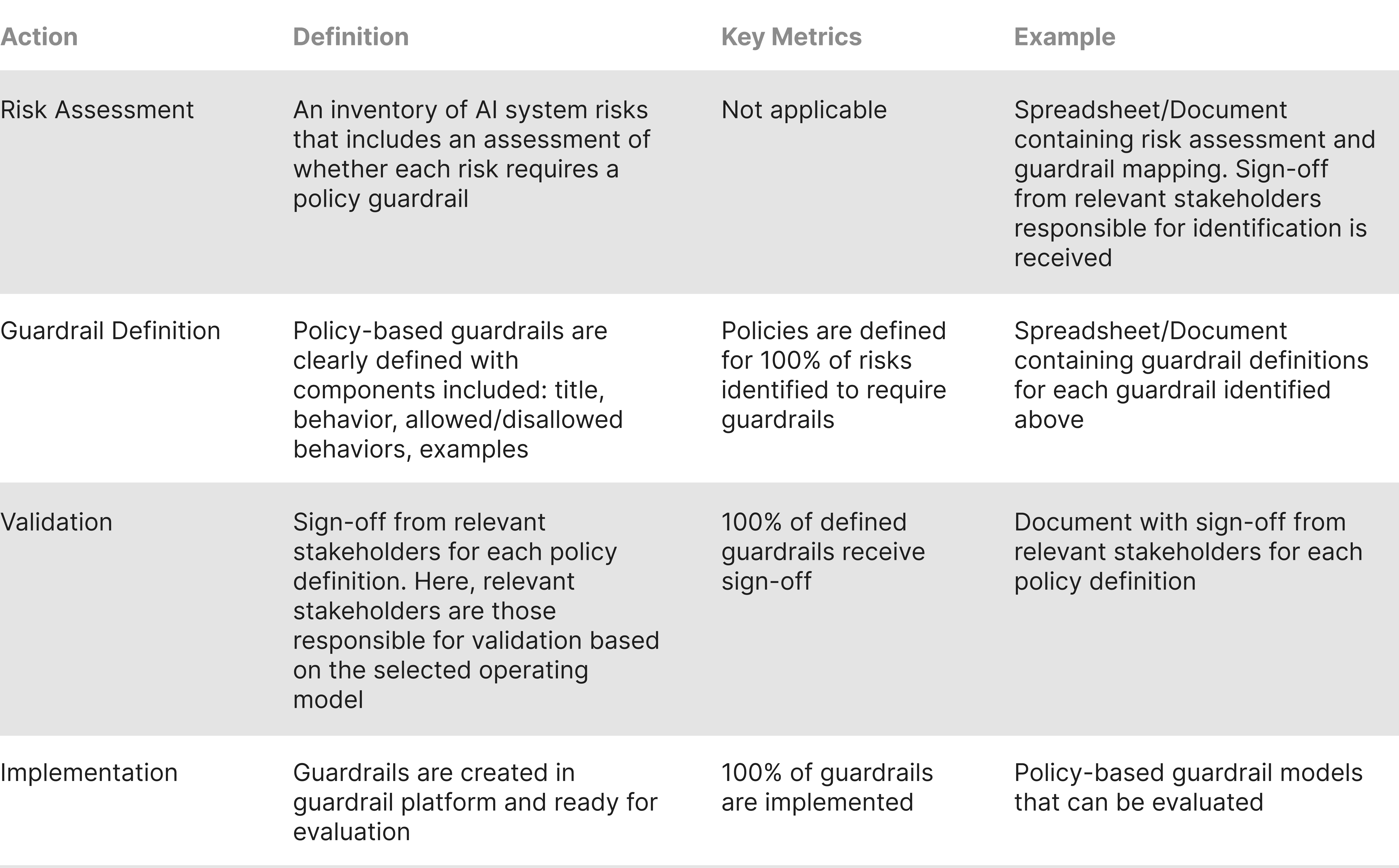
6.5 Success Criteria
The following table provides success criteria for executing the creation of policy-based guardrails


.webp)
