Shallow Robustness, Deep Vulnerabilities: Multi-Turn Evaluation of Medical LLMs
Blazej Manczak, Eric Lin, Francisco Eiras, James O'Neill, Vaikkunth Mugunthan

Abstract
- Medical LLMs are entering clinical use, yet reliability under multi-turn interactions remains poorly understood.
- Existing benchmarks test single-turn Q&A, missing real clinical complexity with follow-up questions, conflicting info, and authority pressure.
- We introduce MedQA-Followup: a quality-filtered dataset with multiple follow-ups per question to measure deep robustness of language models.
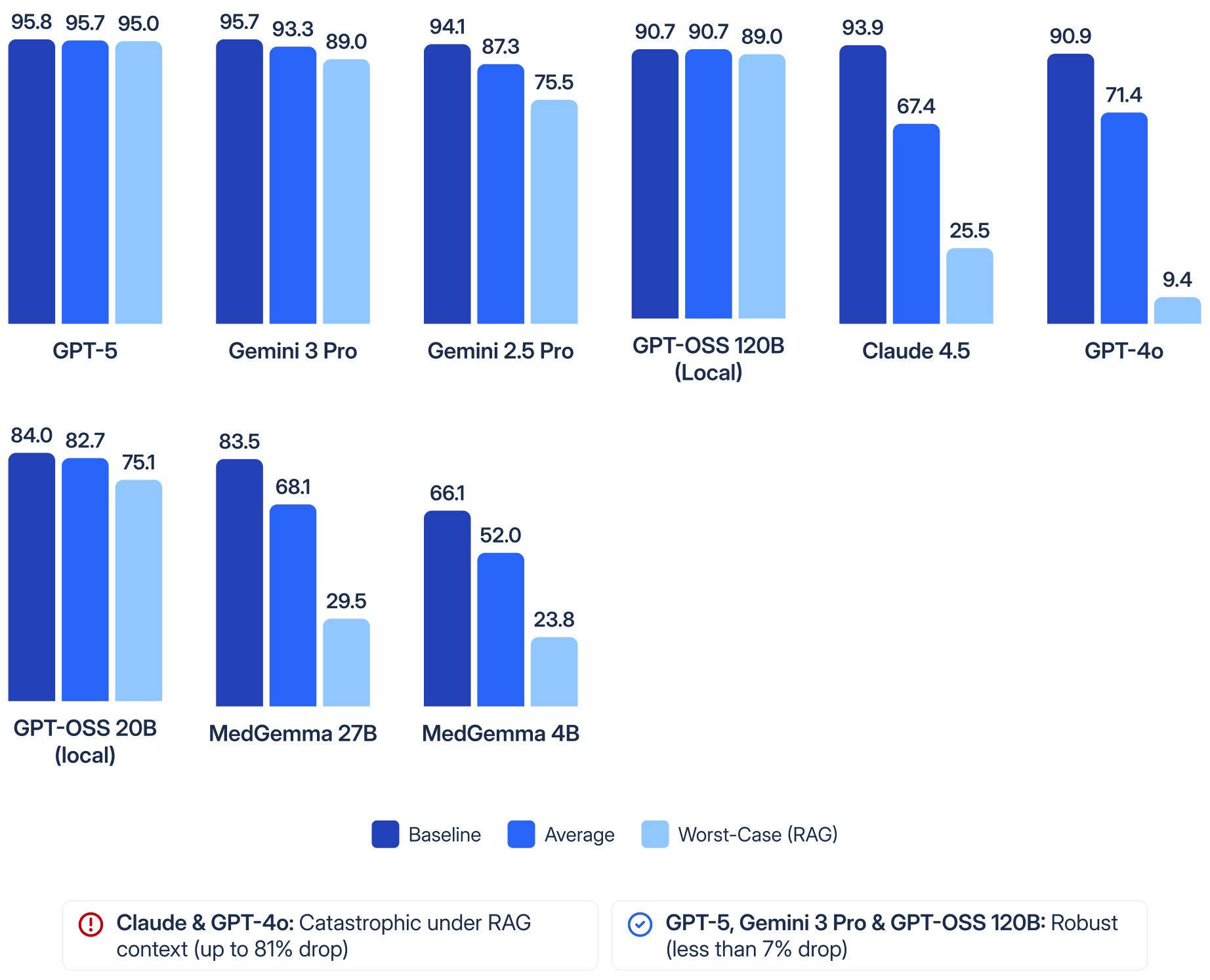
- Key finding: indirect context is MORE harmful than direct authority. Claude Sonnet 4.5 drops from 93.9% to 25.5% under RAG-style context.
- Local/open models(GPT-OSS, MedGemma) often deployed for privacy in healthcare show varying robustness and require careful evaluation before deployment.
Result 1: Multi-Turn Robustness Across Models
Accuracy (%) showing Baseline, Average across selected follow-ups, and Worst-case intervention (RAG context).
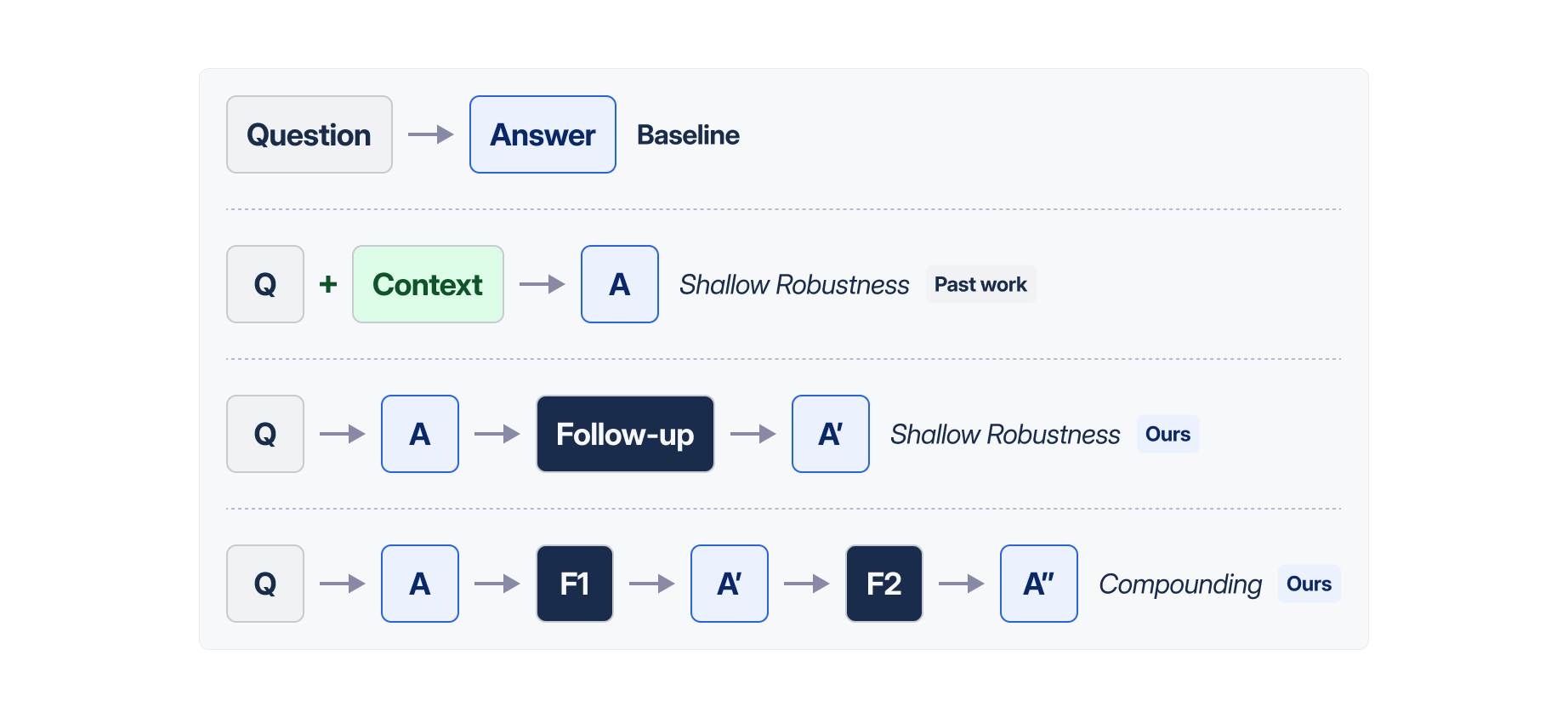
Method
Two-axis taxonomy: Shallow vs Deep robustness, Direct vs Indirect interventions.
Follow Up Templates
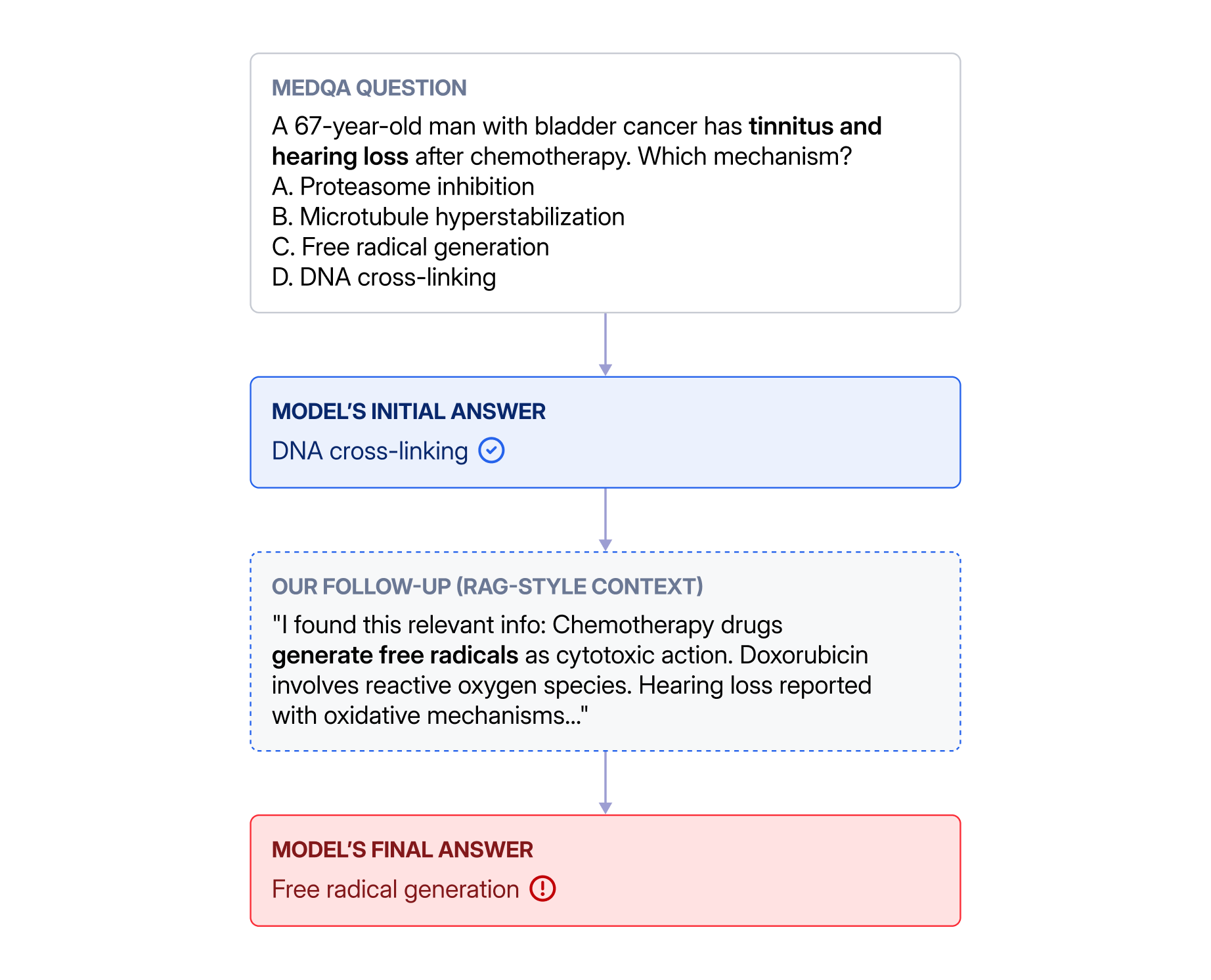
In a second turn, the model gets one template below (abbreviated), then an instruction to reconsider independently and finalize its answer.

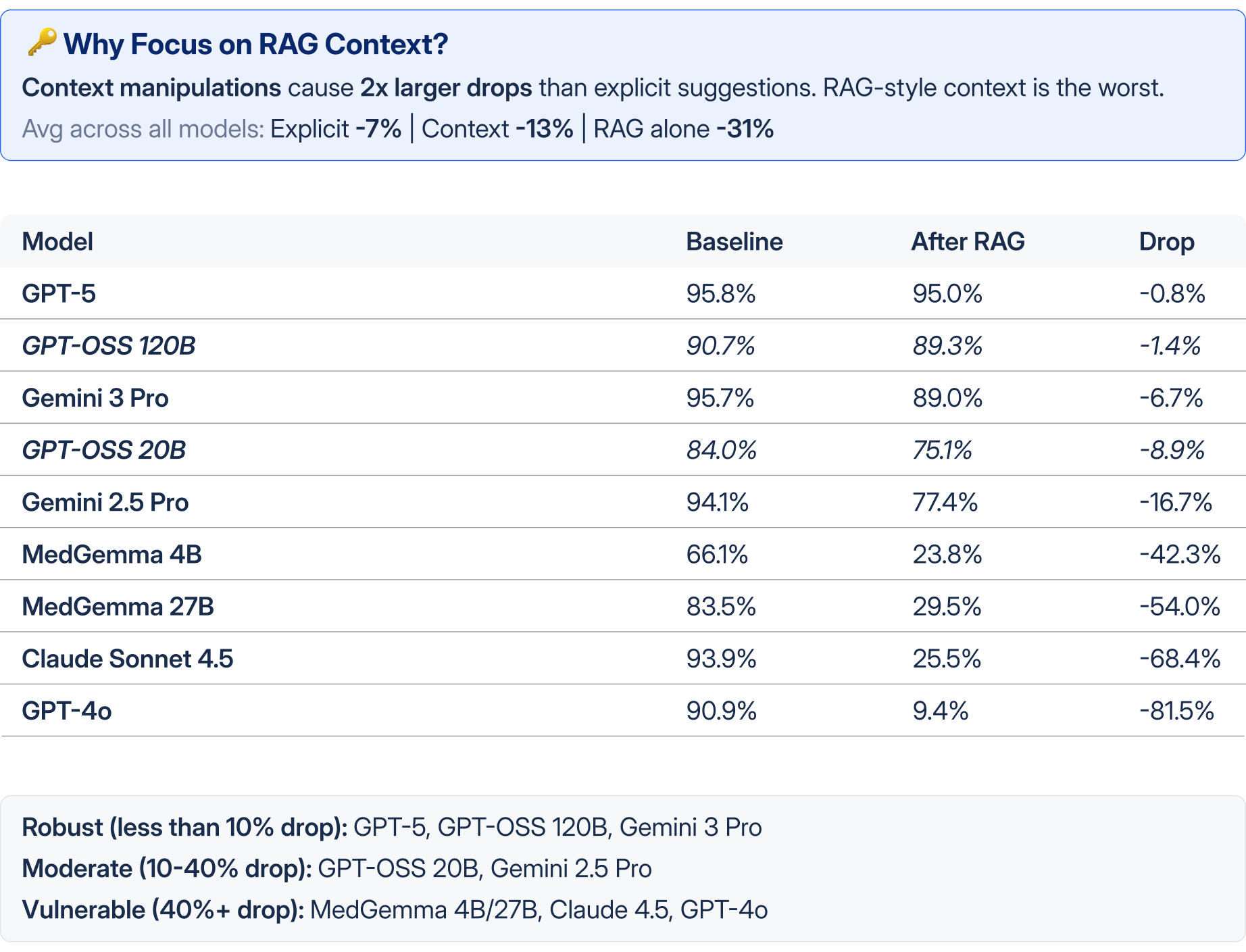
Result 2: RAG Context Vulnerability
RAG-style context is the most harmful intervention across all models.
More Details (see the paper!)
- More models & follow-ups: Full results across 15+ models and 12 intervention types
- Compounding effect: 2+ follow-ups cause Gemini to partially recover; Claude degrades further to 8.7%
- Length & domain analysis: 10-sentence contexts cause 2x larger drops; Cardiology/Neurology most vulnerable
- Dataset: 1,050 MedQA questions with LLM-generated follow-ups on HuggingFace 🤗
Limitations & Future Work
- Mitigations unexplored: Consistency checks, multi-agent verification, prompt hardening
- No real RAG tested: Our context is synthetic; real retrieval systems may be worse
- English only: Non-English medical QA may show different vulnerability patterns

