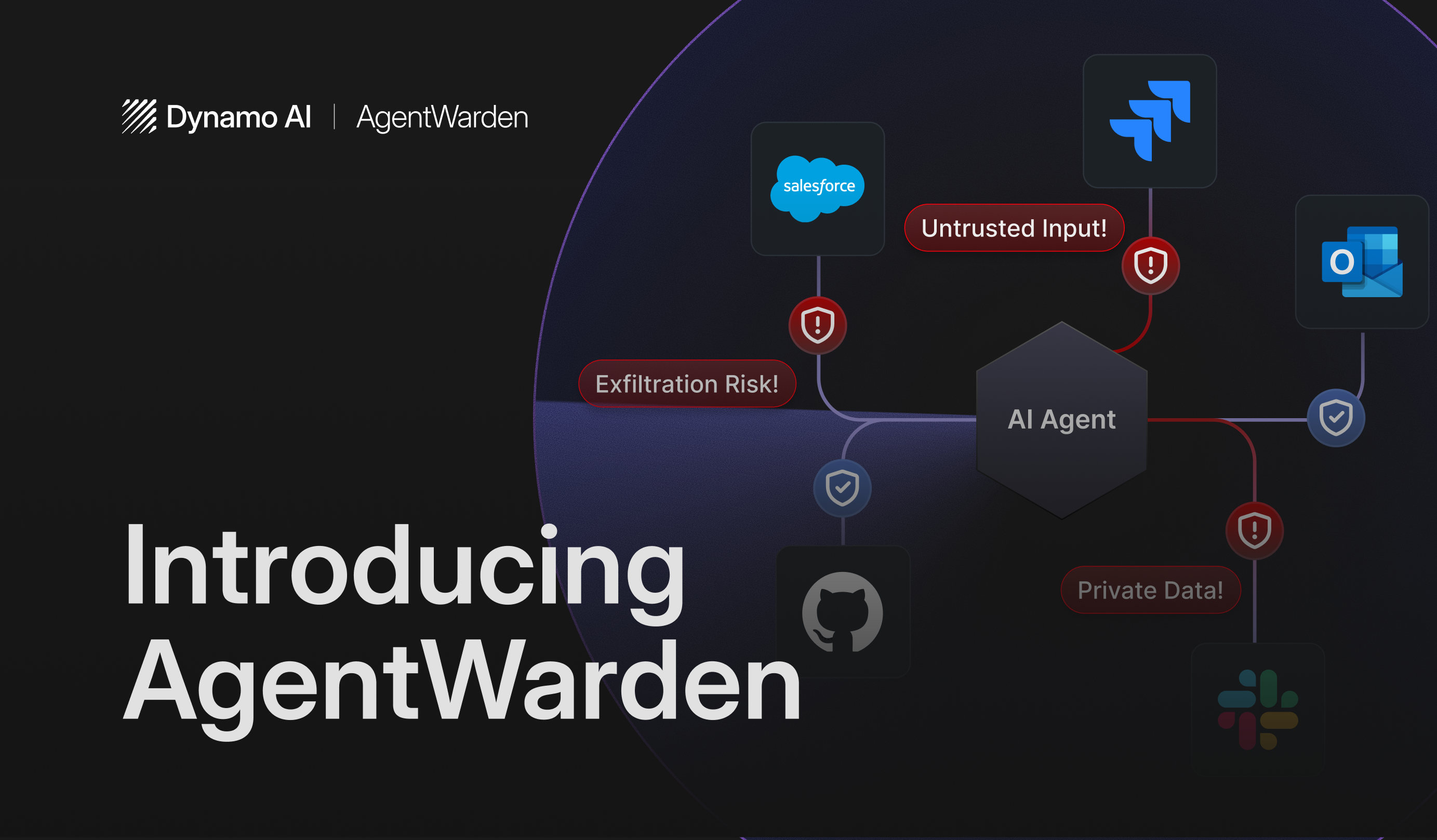
GenAI Controls
Automated AI Evaluations and Red-Teaming
End-to-end, automated AI risk evaluation to measures privacy, safety, and compliance of AI systems to ensure secure, policy-aligned, and trustworthy model deployment.
Security, hallucination, and compliance gaps are stifling your AI production goals.
Dynamo delivers auditable AI guardrails, hallucination checks, red-teaming, and observability so you can productionize generative and agentic AI with confidence.

Automated risk detection and real-time guardrails for auditable reporting and complete observability.
Industry leading AI security guardrails and evaluations constantly updated to defend against jailbreaking and prompt injection vulnerabilities.
Enable legal, risk, compliance, and cyber teams to define custom guardrails tailored to your organizations specific compliance requirements.
Real-time hallucination detection and LLM failure modes, including detailed root cause analysis to remediate problematic LLM responses.




GenAI Controls
End-to-end, automated AI risk evaluation to measures privacy, safety, and compliance of AI systems to ensure secure, policy-aligned, and trustworthy model deployment.

GenAI Controls
Enable legal, risk, compliance, and cyber teams to define custom guardrails tailored to your organizations specific compliance requirements.

GenAI Controls
Real-time hallucinations detection and LLM failure modes, including detailed root cause analysis to remediate problematic LLM responses.

GenAI Controls
Log, audit, and monitor every interaction across home-grown and 3rd party vendor AI Use Cases.

Dynamo’s PaaS product suite offers end-to-end technical controls to accelerate secure and compliant productionization of AI use cases.
Simplify observability for your generative and agentic AI workflows with one unified monitoring platform, providing actionable insights and centralized visibility into AI compliance.

Ensure your policies have comprehensive coverage and detailed writing using our AI-assisted writing tools.

Enhance guardrails and evaluations with human-in-the-loop capabilities, allowing users to review, adjust, and approve guardrail or model evaluation results for greater accuracy and trust.