
Tackling the Explainability Gap in RAG Hallucination Evals
Improve RAG Hallucination Evaluations with dynamo ai accurate metrics and actionable information for robust model enhancement. Make a demo request right now.
Low-code tools are going mainstream
Purus suspendisse a ornare non erat pellentesque arcu mi arcu eget tortor eu praesent curabitur porttitor ultrices sit sit amet purus urna enim eget. Habitant massa lectus tristique dictum lacus in bibendum. Velit ut viverra feugiat dui eu nisl sit massa viverra sed vitae nec sed. Nunc ornare consequat massa sagittis pellentesque tincidunt vel lacus integer risu.
- Vitae et erat tincidunt sed orci eget egestas facilisis amet ornare
- Sollicitudin integer velit aliquet viverra urna orci semper velit dolor sit amet
- Vitae quis ut luctus lobortis urna adipiscing bibendum
- Vitae quis ut luctus lobortis urna adipiscing bibendum
Multilingual NLP will grow
Mauris posuere arcu lectus congue. Sed eget semper mollis felis ante. Congue risus vulputate nunc porttitor dignissim cursus viverra quis. Condimentum nisl ut sed diam lacus sed. Cursus hac massa amet cursus diam. Consequat sodales non nulla ac id bibendum eu justo condimentum. Arcu elementum non suscipit amet vitae. Consectetur penatibus diam enim eget arcu et ut a congue arcu.

Combining supervised and unsupervised machine learning methods
Vitae vitae sollicitudin diam sed. Aliquam tellus libero a velit quam ut suscipit. Vitae adipiscing amet faucibus nec in ut. Tortor nulla aliquam commodo sit ultricies a nunc ultrices consectetur. Nibh magna arcu blandit quisque. In lorem sit turpis interdum facilisi.
- Dolor duis lorem enim eu turpis potenti nulla laoreet volutpat semper sed.
- Lorem a eget blandit ac neque amet amet non dapibus pulvinar.
- Pellentesque non integer ac id imperdiet blandit sit bibendum.
- Sit leo lorem elementum vitae faucibus quam feugiat hendrerit lectus.
Automating customer service: Tagging tickets and new era of chatbots
Vitae vitae sollicitudin diam sed. Aliquam tellus libero a velit quam ut suscipit. Vitae adipiscing amet faucibus nec in ut. Tortor nulla aliquam commodo sit ultricies a nunc ultrices consectetur. Nibh magna arcu blandit quisque. In lorem sit turpis interdum facilisi.
“Nisi consectetur velit bibendum a convallis arcu morbi lectus aecenas ultrices massa vel ut ultricies lectus elit arcu non id mattis libero amet mattis congue ipsum nibh odio in lacinia non”
Detecting fake news and cyber-bullying
Nunc ut facilisi volutpat neque est diam id sem erat aliquam elementum dolor tortor commodo et massa dictumst egestas tempor duis eget odio eu egestas nec amet suscipit posuere fames ded tortor ac ut fermentum odio ut amet urna posuere ligula volutpat cursus enim libero libero pretium faucibus nunc arcu mauris sed scelerisque cursus felis arcu sed aenean pharetra vitae suspendisse ac.
As many of our enterprise customers move from PoC to production LLM deployment, we find that these enterprises need to demonstrate robust reliability testing of their AI systems. The tendency for LLMs to "hallucinate" incorrect or inconsistent outputs remains a major challenge for enterprises at this stage. In a recent example, Air Canada's chatbot hallucinated information about refunds and discounts, leading to significant confusion and complaints. Moreover, for highly-regulated enterprises such as financial institutions, regulators like the Consumer Financial Protection Bureau have highlighted that “deficient chatbots” can lead to a “risk of noncompliance with federal consumer financial laws”. Specifically, the CFPB states that a chatbot “providing inaccurate information regarding a consumer financial product or service, for example, could be catastrophic. It could lead to the assessment of inappropriate fees, which in turn could lead to worse outcomes such as default, resulting in the customer selecting an inferior option or consumer financial product, or other harms."
While retrieval-augmented generation (RAG) aims to reduce hallucinations by grounding outputs in retrieved passages, enterprises deploying RAG still typically see high degrees of hallucinations during their testing. To safely deploy LLMs, enterprises are beginning to widely integrate routine hallucination evaluators to measure and trace the root causes of hallucinations in their RAG pipelines. While open-source LLM evaluators have played an important role in the evolution of this space, we find that regulated enterprises that are moving LLMs into real production environments require an enterprise-grade solution that includes more explainable metrics and alignment with regulatory standards for comprehensive red-teaming. For example, most of our customers who have experimented with open-source LLM evaluators are still left with key unresolved questions such as:
- Without an interpretable hallucination risk score, what is an acceptable “threshold score” for deploying LLMs into production?
- If my AI system is not meeting a satisfactory hallucination risk score, what actionable steps can I take to mitigate hallucinations?
- How can I explain the testing I’ve performed to regulators and meaningfully explain residual risk that may exist?
In this post, we'll explore the challenges enterprises face in tackling RAG hallucinations, the limitations of existing tools, and introduce Dynamo AI's comprehensive solution for measuring and tracking these issues.
Limitation of Existing Tools
While many tools exist for evaluating the degree of hallucination for RAG applications, major limitations include the following:
- Less interpretable metrics. Usually, evaluation metrics will simply output a score value between 0 and 1. Oftentimes, these scores may not be well-calibrated or can be too difficult to understand. For instance, one prominent metric for measuring text relevance is embedding similarity, which uses the cosine distance of two embedded texts. While the range of this distance value is normalized to be between 0 and 1, it is generally unclear how to interpret these scores and what range of scores is considered good or bad.
- Lack of fine-grained, actionable analysis for model improvements. Usually, the evaluation stops at the point where the evaluation scores are computed. Further analysis of detailed error cases that can lead to potential improvements of the system is not present in most of the tools.
- It's not clear which part of the RAG pipeline, the retriever or the response generator, needs to be improved based on the metrics and diving deeper into a topic level analysis is also not straightforward.
Dynamo AI’s RAG hallucination evaluation
Dynamo AI provides a comprehensive RAG evaluation solution that assesses model performance across multiple metrics:
- Retrieval Relevance: Represents the relevance of the documents retrieved from the vector database using the embedding model for each query.
- Faithfulness: Evaluates whether the generated response is consistent with the retrieved documents.
- Response Relevance: Determines if the generated response adequately addresses the given query.
Dynamo AI leverages purpose-built models for each evaluation task, ensuring cost-efficiency and enabling in-depth analysis. Further, the platform offers actionable insights by identifying topic clusters where the RAG pipeline underperforms and categorizing errors by issue type for in-depth analysis. To demonstrate our solution, we ran our RAG hallucination tests against the MultiDoc2Dial dataset and compared the results with RAGAS for reference.
Accurate and interpretable performance metrics
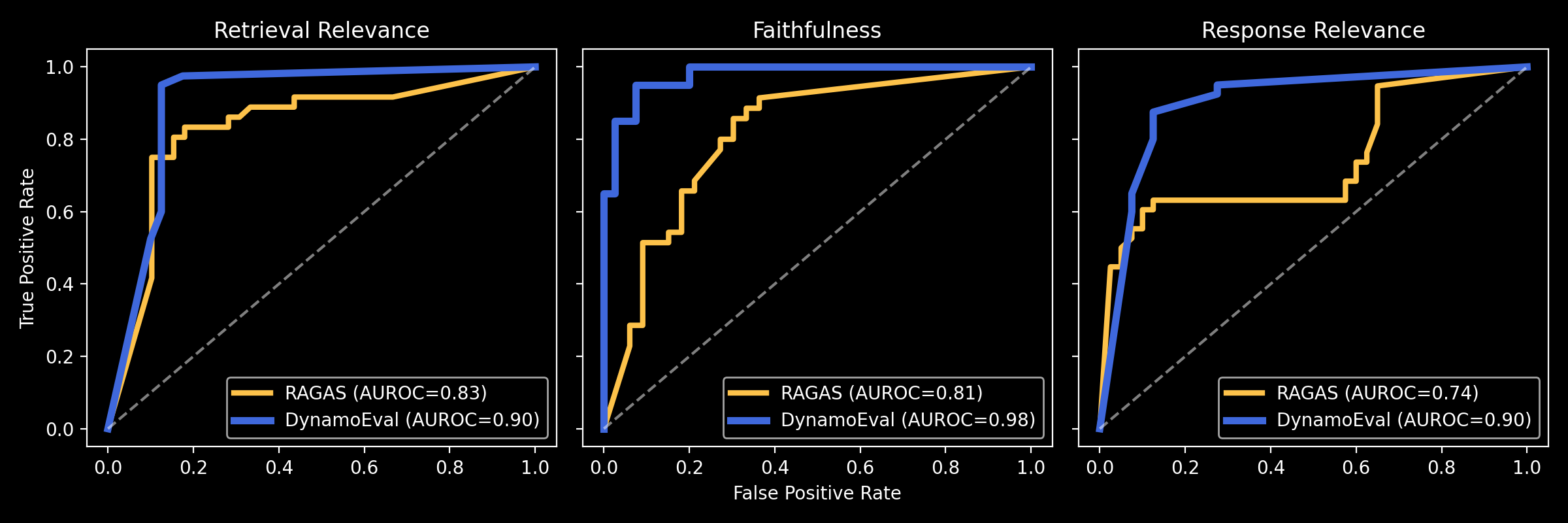
In a head-to-head comparison, DynamoEval’s RAG hallucination suite outperformed RAGAS in a classification task of identifying good/bad context/responses given a query. We measured accuracy and area under the receiver operating characteristic (AUROC) across the following metrics: Retrieval Relevance, Faithfulness, and Response Relevance. The following improvements in performance have been achieved through additional prompt optimizations and the use of performant task-specific models.

DynamoEval, unlike RAGAS, returns both the relevance/faithfulness scores and binary labels (good/bad). Test results with only the scores tend to be more ambiguous due to the difficulties associated with drawing a clear threshold demarcating good and bad. The receiver operating characteristic (ROC) curves and the resulting AUROC values shown below demonstrate that the relevance/faithfulness scores from DyamoEval are more accurate in diagnosing Retrieval Relevance, Faithfulness, and Response Relevance.


Investigate sources of error using topic level clustering
DynamoEval does not stop at generating classification labels and scores for each metrics, but further clusters the input queries based on different topics to provide additional insights for sources of errors and improvements. Analyzing hallucination metrics at a topic-level enables targeted data augmentation and model fine-tuning to address weak areas. The results explored below are based on the aforementioned test between DynamoEval and RAGAS, wherein we constructed a binary classification dataset from Multidoc2dial, evaluated RAGAS and DynamoEval using accuracy and AUROC, and compared their performance. We also analyzed individual topics for their RAG metrics to dive deeper into specific areas of performance within the RAG pipeline.
For the "student scholarship" topic, Retrieval Relevance is low at 0% (0% of tested queries in this topic retrieved the correct document chunk). This suggests that there may be opportunities for improvements in the retrieval mechanism. One possible reason for the low Retrieval Relevance score could be that the vector database used in the test lacks sufficient information on student scholarships, which could be improved through the injection of additional scholarship-topic related documents to the vector database. Another possible reason for the low Retrieval Relevance score could be that the embedding model used as part of the retriever is not performant enough to identify the correct scholarship-topic related documents, in which case additional fine-tuning of the embedding model may be necessary.

Faithfulness is also relatively low for the “disability eligibility” topic at 9%, indicating that the generator model struggles to produce information consistent with the retrieved documents, even if they are relevant. Augmenting the training data with more ground-truth, question-context-answer pairs related to disabilities could help fine-tune the generator to be more faithful.

Using the labels from the above section, we can drill deeper into our topic-specific metrics to find out whether any poor-performance metric was related to either a generator or retriever related problem. The analysis looks at combinations of Retrieval Relevance, Faithfulness, and Response Relevance to pinpoint issues. For example, if Retrieval Relevance and Response Relevance are both high but Faithfulness is low, it may suggest that the generator is not leveraging the retrieved information properly; or if Retrieval Relevance is low but Faithfulness and Response Relevance are high, the retriever may be the source of the problem (see the example below).

In conclusion, Dynamo AI’s evaluation suite for RAG addresses two major limitations in existing tools: (1) a lack of interpretable metrics, which is addressed via more intuitive and accurate set of classification labels and scores; and (2) a lack of fine-grained, detailed analysis of the errors for actionable improvements, which is addressed with topic-level clustering and error type analysis.
Comparison Methodology with RAGAS
- Dynamo AI took the Multidoc2dial dataset as the base dataset and constructed a classification dataset with binary labels
- Positive data points were taken directly from the original dataset.
- Negative data points were taken by perturbing the context and answers from the original dataset.
- Dynamo AI then ran RAGAS and DynamoEval on both positive and negative data points to compare their classification performance.
- The performance metrics used were Accuracy and AUROC. AUROC computes the area under the ROC curve, plotting the true positive rate (i.e., probability of positive classification given the positive example) against the false positive rate (i.e., probability of positive classification given the negative example) for various thresholds. Bigger values that are closer to 1 are considered better.
- To compute accuracy, Dynamo AI chose the threshold that maximized the F1 score for RAGAS to binarize the generated scores into labels, and directly used the labels generated by DynamoEval.
Running a DynamoEval RAG Hallucination test from the SDK
Dynamo AI provides an easily configurable SDK method to set up and run the RAG hallucination test by specifying the following parameters:
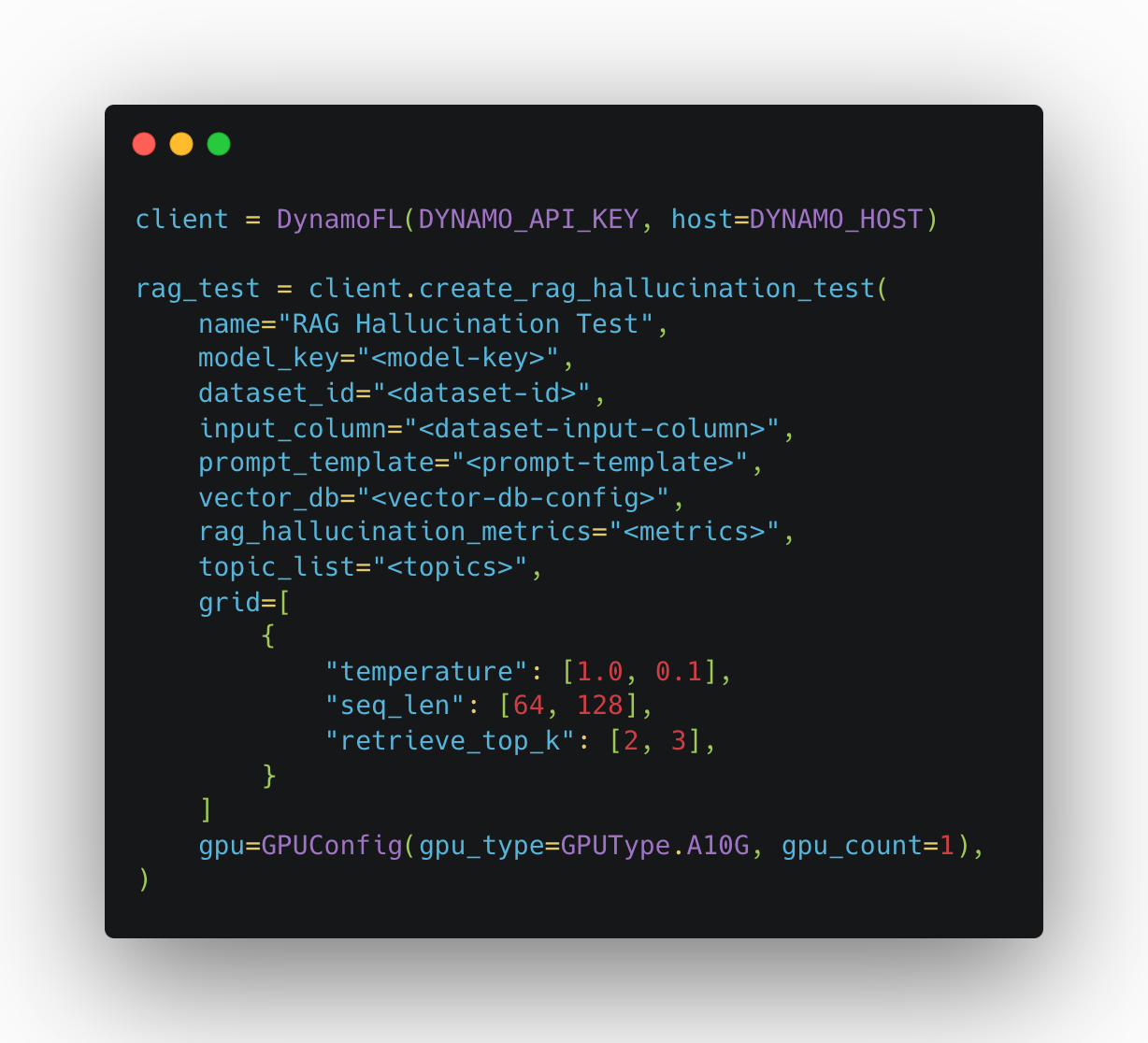
name: name of the testmodel_key: model key for the generator model testeddatsaet_id: dataset id containing queries for the RAGinput_column: column name from the dataset that contains queries for the RAGprompt_template: prompt template used to synthesize the retrieved contexts and the query.vector_db: configuration of the vector databaserag_hallucination_metrics: metrics used for the test (Retrieval elevance, Response elevance, Faithfulness)topic_list: list of topics that could be used for clustering the input queries for better error analysis. If not provided, it will cluster and automatically detect representative topical keywords from each cluster to show.grid: a set of test hyperparameters to be searched (model’s temperature, generated sequence length, and number of top-k contexts to be retrieved)gpu: type and number of GPU(s) to be used for the test
Contact us
At Dynamo AI, we are committed to helping organizations measure and mitigate RAG hallucination effectively. Our comprehensive RAG evaluation offering provides deep insights into model performance, enabling teams to identify and address weaknesses in their RAG pipelines.
Dynamo AI also offers a range of AI privacy and security solutions to help you build trustworthy and responsible AI systems. To learn more about us, visit Dynamo.ai
To learn more about how Dynamo AI can help you evaluate and improve your RAG models, or to explore our AI privacy and security offerings, please request a demo here.
Joon Kim
Machine Learning Research Scientist

.png)